Welcome Platform: A Bird’s-Eye View
The WELCOME platform prototype has been developed to meet the needs of public authorities and non-governmental organisations to facilitate support to the TCNs living in the EU. In this article, we show the high-level architecture of the platform, provide an overview of its components and the flows and interactions within it; and touch on aspects of deployment and security.
Oleksandr Sobko, Víctor Marín Puchades, Moisés Francisco Gómez Izquierdo, Daniel Antonio Bowen Vera (NTTDATA), Barcelona (Spain),
Introduction
For the last 30 years, software has become ubiquitous. From your dishwasher to your smartphone, a wide host of daily used devices meant to make our lives easier need software to deliver the functionalities they were designed for. Moreover, these functionalities are oftentimes spread along with different software building blocks which perform more concrete but essential actions that compose the final product catering to the user. This is the case of the software developed in the WELCOME project and what we will refer to as the WELCOME platform.
The needs of WELCOME are to develop intelligent technologies to support the reception and integration of Third Country Nationals (TCNs) in Europe. The approach is to offer a personalized and multilingual solution for migrants, asylum seekers, and refugees and public administrations that provides intelligent services to facilitate TCNs’ learning in the following domains: registration and orientation, social and societal inclusion, information about legislations and living in the host country, among others. The TCN should be able to perform different tasks easily through a dialog mode (by voice and/or by text) in the host country’s language or their mother tongues in the WELCOME mobile application (MyWELCOME App).
In this article, we intend to provide, in layman’s terms, a bird’s eye view of the WELCOME Platform and its components. The first section will introduce the software architecture, that is, the software puzzle pieces behind WELCOME that accomplish, among other things, that the TCNs can refer their needs or questions to a smartphone application (i.e., the MyWELCOME App) backed by an intelligent agent and they receive an appropriate response. The second section will delve into how these software pieces are packaged and enabled to work together. Finally, the third section will outline some of the security concerns and solutions implemented in Welcome to keep TCNs personal data isolated and safe.
Architecture
The term architecture might sound confusing in this context to people unfamiliar with software development terminology. However, it essentially refers to the process of organising (the construction of) a software system, which comprises its components and other building blocks, in this instance, the WELCOME Platform. The ISO 42010 standard provides the following definition of architecture: the fundamental organization of a system, embodied in its components, their relationships to each other and to the environment, and the principles governing its design and evolution.
The WELCOME solution requires immersive and intelligent technologies for linguistic analysis, dialog management, generation of audio from text, and so on. It should be noted that this article does not provide a comprehensive detailed solution design. The whole platform is composed of more than 20 components that utilise different technologies. This description is focused on the most important architectural decisions that define the conceptual model of the WELCOME platform.
The core of the platform is the Agent-Driven Service Coordination (ADSC) component that consists of three subcomponents: the agent-core for behaviour tree-based deliberative decision-making and action coordination, the Semantic Service Computing (SSC) for selection and composition planning of relevant services, and the agent-KMS for maintaining and reasoning on local agent knowledge. Local agent knowledge about the domain, context and TCN, the available social services, and other MyWELCOME agents in the WELCOME platform are stored in the local repositories.
The solution architecture of the platform follows the pipeline pattern which is a software design pattern that enables the execution of a sequence of operations dynamically. Figure 1 depicts the initial version of the workflow that has been implemented in the first prototype of the platform. The workflow is composed of two pipelines: the first pipeline carries out the linguistic analysis of the TCN speech, while the second one is aimed at providing a response to the TCN request terms of a dialogue move.
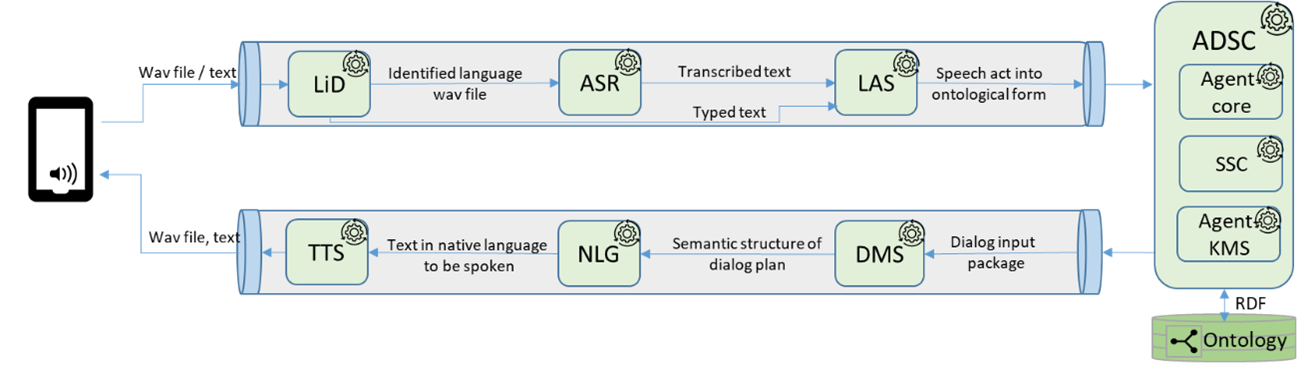
The first pipeline is composed of two or three steps depending on the type of the input: text or audio:
1. A TCN’s utterance or a text is analysed by the Language Identification (LiD).
2. An audio file and identified language are delivered to the Automatic Speech Recognition (ASR) module for speech recognition. This step could be missed if the TCN uses the text mode.
3. The text is provided to the Language Analysis Service (LAS) to transform the TCN request into speech acts in an ontological format that is used in the request to the Agent-Driven Service Coordination (ADSC).
The Agent analyses speech acts, updates the local ontology with information, service request, and dialogue history, and creates a Dialog Input Package (DIP) for each speech act using dialogue context knowledge and semantic service for TCN requests.
The second pipeline receives DIPs as input from the Agent and produces dialogue moves to be rendered as spoken language:
1. The Dialogue Management Service (DMS) applies dialogue policies to plan dialogue moves in order to produce an agent utterance content.
2. The Natural Language Generation (NLG) takes as input the structure provided by the DMS and generates the statements to be uttered by the agent.
3. And finally, the Text-To-Speech (TTS) takes as input the statements generated by the NLG component; the output is audio that is spoken in the presentation layer (MyWELCOME App).
This workflow created a simple skeleton, a basis for creating more complex flows. It implemented an end-to-end system to validate and demonstrate the spoken language analysis and generation, semantic coordination, and dialogue management capabilities. It was important to demonstrate the ways these components inter-communicate, as such a data flow was created with the cooperation of all technical partners and with consideration to approving the previously designed solution architecture.
Figure 2 depicts the enhanced workflow that depends on the spoken language. The intention is to improve the quality of speech recognition and use language-specific instances of the Automatic Speech Recognition (ASR).
The Language Identification (LiD) identifies the probability of language of the speech. Then the Knowledge Management System (KMS) makes a final decision about the language of the dialog. The KMS takes into account the user’s mother tongue if the LiD has not identified the language with the required probability (probability has not reached a pre-defined threshold, e.g. probability less than 50%). Then the data is routed to one of the language-specific instances of the Automatic Speech Recognition (ASR). In this particular case, there are three ARS instances: Greek, German, and Catalan, which transcribe the audio to text. Then, the Machine Translation (MT) component translates the transcribed text into English language. Finally, the Language Analysis Service (LAS) forms the text speech act in terms of a predicate-argument structure as an ontological (RDF-triple based) representation.
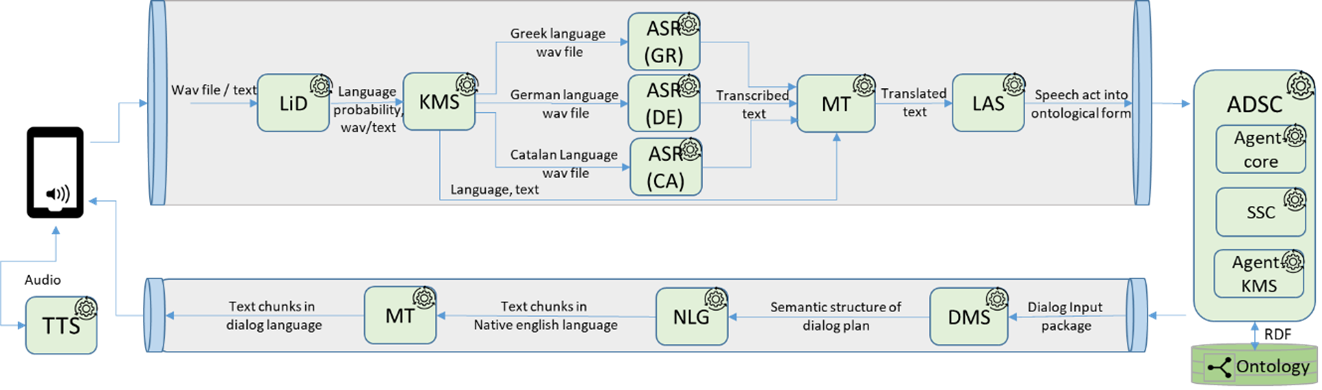
The reverse flow also has been modified. The Machine Translation (MT) translates the Natural Language Generation (NLG) output in English to the dialog language that has been identified by the Language Identification (LiD) and Knowledge Management System (KMS). The entire response has been divided into smaller text chunks in order to reduce the latency in the dialog. The Text-To-Speech (TTS) has been moved out from the pipeline also for the reason of performance. The synthesis of audio from text is a rather heavy and time-consuming operation.
These examples of workflows demonstrate the flexibility of the solution. Customizing the system is simple. The pipeline can be modified easily and allows combining different components and technologies into a holistic platform.
Another advantage of the proposed architecture is to enable black box testing. It means testing without having knowledge of internal code structure, implementation details, and internal paths.
Knowing the expected input and output of each component allows us to test the components separately, and together in a pipeline, or a piece of a pipeline.
For example, the audio files recorded by the users were used to test and improve the quality of the linguistic analysis components.
Deployment
Deploying software refers to making it available to the users by placing the software in the runtime environment and executing it. Moreover, for software to function successfully, several technical assumptions about the runtime environment need to fall into place. Therefore, deploying several components in one environment requires that these technical assumptions for all the components are all met in one environment, which is not necessarily an easy task.
In the case of the WELCOME project, the software is deployed in the Cloud with the same runtime environment. In order to overcome the issue of different technical assumptions between components, each one of these is packaged in a runtime environment that fulfils the expected requirements, which is usually referred to a container. Moreover, containerization makes it possible to encapsulate and isolate each of the different applications that make up the component so that they are independent. Some of the advantages it offers:
- Allows running on any operating system
- Each container can be modified, deleted, or moved without losing its functions or affecting the rest of the containers.
- They can be executed in a local environment, in virtual machines, or in the cloud.
Working with containers helps us in the development and maintenance of the platform thanks to their flexibility and increased security.
For the management and creation of containers in Welcome, we use Docker [1]. Docker is open-source software that provides a desktop application and a Linux-based console for all container management such as creating, starting, stopping, modifying, or removing them. Containers are created from images that contain the packaged software (i.e., in a way, similar to the one contained in a CD-ROM that runs a program). This support stores all the information to be able to install and run a program in the same way as a container image to be able to run it.
Security
From the beginning, particular attention had been given to the security of the platform, especially in order to be compliant with GDPR.
The Hypertext Transfer Protocol Secure (HTTPS) is used to provide a secure transport mechanism for the messages exchanged through the internet. TLS certificates are issued by the nonprofit LetsEncrypt Certificate Authority (CA).
The users have to be authorised to have access to the platform functionality. The OpenID Connect (OIDC) is implemented to verify the identity of the users based on the authentication performed by the Keycloak module.
Conclusion
Most of the language technologies used in the project are still in the process of research and testing. Our solution design provides a high degree of flexibility and agility. It enables us to more easily modify the workflow and add or replace the components in the pipeline. For example, the workflow can vary depending on the language of speech or type of input. However, the disadvantage of this design is the risk of a significant latency between a TCN’s action and a platform response. That is why performance optimisation is one of the critical aspects of our work. Our further development will be also focused on new digital services which are very important for reducing barriers for the TCNs in their integration into the European community in the covid-19 pandemic environment.
Foot notes:
[1] https://www.docker.com/